Researchers have uncovered a surprising connection between a cancer-related signaling pathway and the blood-brain and blood-retina barriers.


Caltech scientists have found a fast and efficient way to add up large numbers of Feynman diagrams, the simple drawings physicists use to represent particle interactions. The new method has already enabled the researchers to solve a longstanding problem in the materials science and physics worlds known as the polaron problem, giving scientists and engineers a way to predict how electrons will flow in certain materials, both conventional and quantum.
In the 1940s, physicist Richard Feynman first proposed a way to represent the various interactions that take place between electrons, photons, and other fundamental particles using 2D drawings that involve straight and wavy lines intersecting at vertices. Though they look simple, these Feynman diagrams allow scientists to calculate the probability that a particular collision, or scattering, will take place between particles.
Since particles can interact in many ways, many different diagrams are needed to depict every possible interaction. And each diagram represents a mathematical expression. Therefore, by summing all the possible diagrams, scientists can arrive at quantitative values related to particular interactions and scattering probabilities.
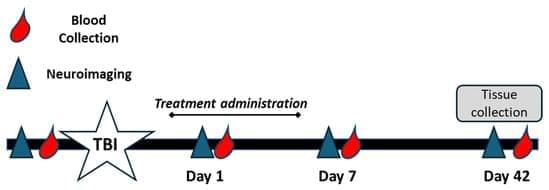
Background/Objectives: Traumatic brain injury (TBI) is a global leading cause of disability and death, with millions of new cases added each year. Oxidative stress significantly exacerbates primary TBI, leading to increased levels of intracerebral cell death, tissue loss, and long-term functional deficits in surviving patients. Catalase and superoxide dismutase (SOD) mitigate oxidative stress and play a critical role in dampening injury severity. This study examines the neuroprotective effects of the novel antioxidant alpha lipoic acid-based therapeutic, CMX-2043, on antioxidant enzymes in a preclinical TBI model via various drug administration routes. Methods: Piglets (n = 28) underwent cortical controlled impact to induce moderate–severe TBI and were assigned to placebo (n = 10), subcutaneous CMX-2043 (SQ, 10 mg/kg; n = 9), or intravenous CMX-2043 (IV, 9 mg/kg; n = 9) treatment groups. Treatments began 1 h after TBI induction and continued for 5 days. MRI was performed throughout the study period to evaluate brain recovery. Blood was collected at 1, 7, and 42 days post-TBI, and liver and brain tissues were collected at 42 days post-TBI to measure catalase and SOD activity. Results: CMX-2043 IV-treated piglets showed 46.3% higher hepatic catalase activity than placebo (p = 0.0038), while the SQ group did not show significant changes in hepatic catalase activity compared to placebo. In the brain, SQ-treated piglets had significantly higher catalase activity than both IV (p = 0.0163) and placebo (p = 0.0003) groups (45.8340 ± 3.0855, 36.4822 ± 1.5558, 31.6524 ± 1.3129 nmol/min/mg protein for SQ, IV, and placebo, respectively), while IV-treated piglets did not show significant changes compared to placebo. IV-treated piglets did exhibit 39.3% higher brain SOD activity than placebo (p = 0.0148), while the SQ group did not show a significant change. CMX-2043 treatment did not alter plasma antioxidant enzyme activity during the study period. Importantly, within CMX-2043 treated TBI groups, piglets with significantly decreased lesion volumes, midline shift, and combined swelling and atrophy had better brain recovery, determined by MRI on day 1, 7, and 42 days post-injury TBI, exhibited higher brain catalase activity at 42 days post-injury TBI regardless of administration route, suggesting a link between improved recovery and sustained local catalase activity. Conclusions: This study highlights the impact of administration route on tissue-specific antioxidant responses, with IV administration enhancing liver catalase and brain SOD activity, while SQ administration primarily elevated brain catalase activity. In addition, this study shows an association between increased brain catalase activity and decreased TBI brain lesioning, midline shift, and combined swelling and atrophy, thus emphasizing the role of antioxidant defenses in neuroprotection post-injury.

Comparing our findings across species with those across growth led us to a final question. If the purpose of sleep shifts from being about neural reorganisation as children to being about repair once we’re grown, when exactly does that transition occur, and how sudden is it? Armed with our new theory plus human developmental data, we could answer this question with surprising accuracy: the transition occurs when we’re extremely young – at about 2.5 years of age – and it happens extremely abruptly, like water freezing at 0°C.
We were delighted with this stunning result. First, it gave us an even greater appreciation for the critical importance of sleep: never again would we underestimate its importance for our children, especially in their first few years of life when their sleep is doing something so fundamentally different and extraordinarily important, something that seemingly can’t be made up for later in life. Second, we had discovered that these two states of sleep, while they looked remarkably similar from the outside, are actually analogous to completely different states of matter before and after the stark dividing line of 2.5 years of age. Before 2.5 years, our brains are more fluid and plastic, enabling us to learn and adapt quickly, similar to the state of water flowing around obstacles. After 2.5 years, our brains are much more crystalline and frozen, still capable of learning and adapting but more like glaciers slowly pushing across a landscape.
Many questions still remain. How much does sleep vary across humans and across species? Can this early fluid phase of sleep be extended? Is this phase already extended or shortened in some individuals, and what costs or benefits are associated with that? What other functions of sleep have piggybacked on to the primary functions of repair and neural reorganisation? How do the different reasons for sleep compete for or share sleep time, either across ages or even within a single night? It will take much more work to fully unravel the mysteries of sleep, but our recent insights – about age-based shifts in the purpose of sleep and the mathematical, predictive theories that quantify them – represent an essential tool to plumb these depths even further.
Quantum Computing Innovation In Pharma — Dr. Thomas Ehmer, Ph.D. — Merck KGaA, Darmstadt, Germany
Dr. Thomas Ehmer, Ph.D. (https://www.linkedin.com/in/tehmer/) is a seasoned technology strategist with over two decades of experience in IT innovation, business development, and R&D within the pharmaceutical industry, and co-founder of the Quantum Interest Group, at Merck KGaA Darmstadt, Germany (https://www.emdgroup.com/en).
Dr. Ehmer currently is in the Sector Data Office — AI Governance and Innovation Incubator at Merck KGaA Darmstadt, Germany, where he scouts emerging and disruptive technologies, demonstrating their potential value for R&D applications, with a focus on quantum technologies.
Throughout his career at Merck KGaA Darmstadt, Germany, Dr. Ehmer has played a pivotal role in shaping IT strategy, business process optimization, and digital transformation across the entire pharmaceutical value chain, currently focusing on transparent AI and how and where emerging technology can help patients live a better life. His expertise spans technology scouting, business analysis, and IT program leadership, having successfully driven major global projects.
Beyond his corporate career, Dr. Ehmer is an active private seed investor and has contributed to quantum computing research and applications in drug discovery, authoring publications on the potential of quantum computing and machine learning in pharmaceutical R&D (https://onlinelibrary.wiley.com/doi/10.1002/9783527840748.ch26).
Joscha Bach (Executive Director) and Lou de K (VP of Programs) interview our scientific advisor Michael Levin on how he would go about testing for consciousness.
Nerve cells are not just nerve cells. Depending on how finely we distinguish, there are several hundred to several thousand different types of nerve cells in the human brain, according to the latest calculations. These cell types vary in their function, in the number and length of their cellular appendages, and in their interconnections. They emit different neurotransmitters into our synapses, and depending on the region of the brain—for example, the cerebral cortex or the midbrain—different cell types are active.
When scientists produced nerve cells from stem cells in Petri dishes for their experiments in the past, it was not possible to take their vast diversity into account. Until now, researchers had only developed procedures for growing a few dozen different types of nerve cell in vitro. They achieved this using genetic engineering or by adding signaling molecules to activate particular cellular signaling pathways. However, they never got close to achieving the diversity of hundreds or thousands of different nerve cell types that actually exist.
“Neurons derived from stem cells are frequently used to study diseases. But up to now, researchers have often ignored which precise types of neuron they are working with,” says Barbara Treutlein, Professor at the Department of Biosystems Science and Engineering at ETH Zurich in Basel.

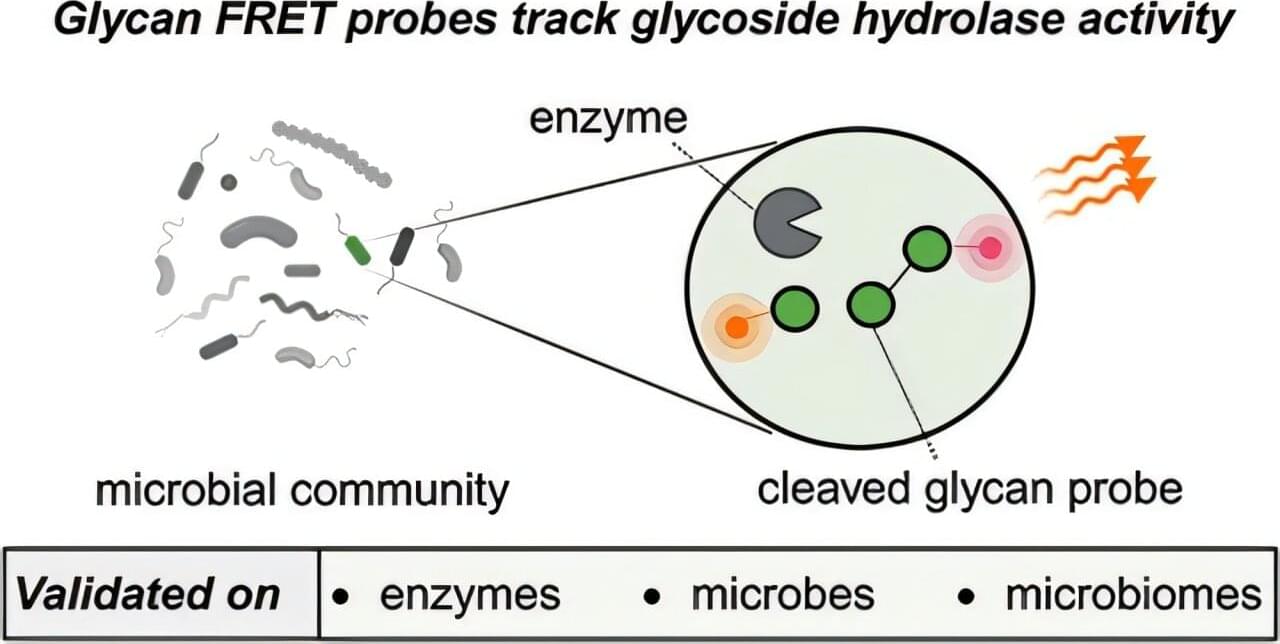
A team of chemists, microbiologists and ecologists has designed a molecular probe (a molecule designed to detect proteins or DNA inside an organism, for example) that lights up when a sugar is consumed.
In the Journal of the American Chemical Society, they now describe how the probe helps researchers study the microscopic tug-of-war between algae and microbial degraders in the ocean.
“Sugars are ubiquitous in marine ecosystems, yet it’s still unclear whether or how microbes can degrade them all,” says Jan-Hendrik Hehemann from the Max Planck Institute for Marine Microbiology and the MARUM—Center for Marine Environmental Sciences, both located in Bremen.