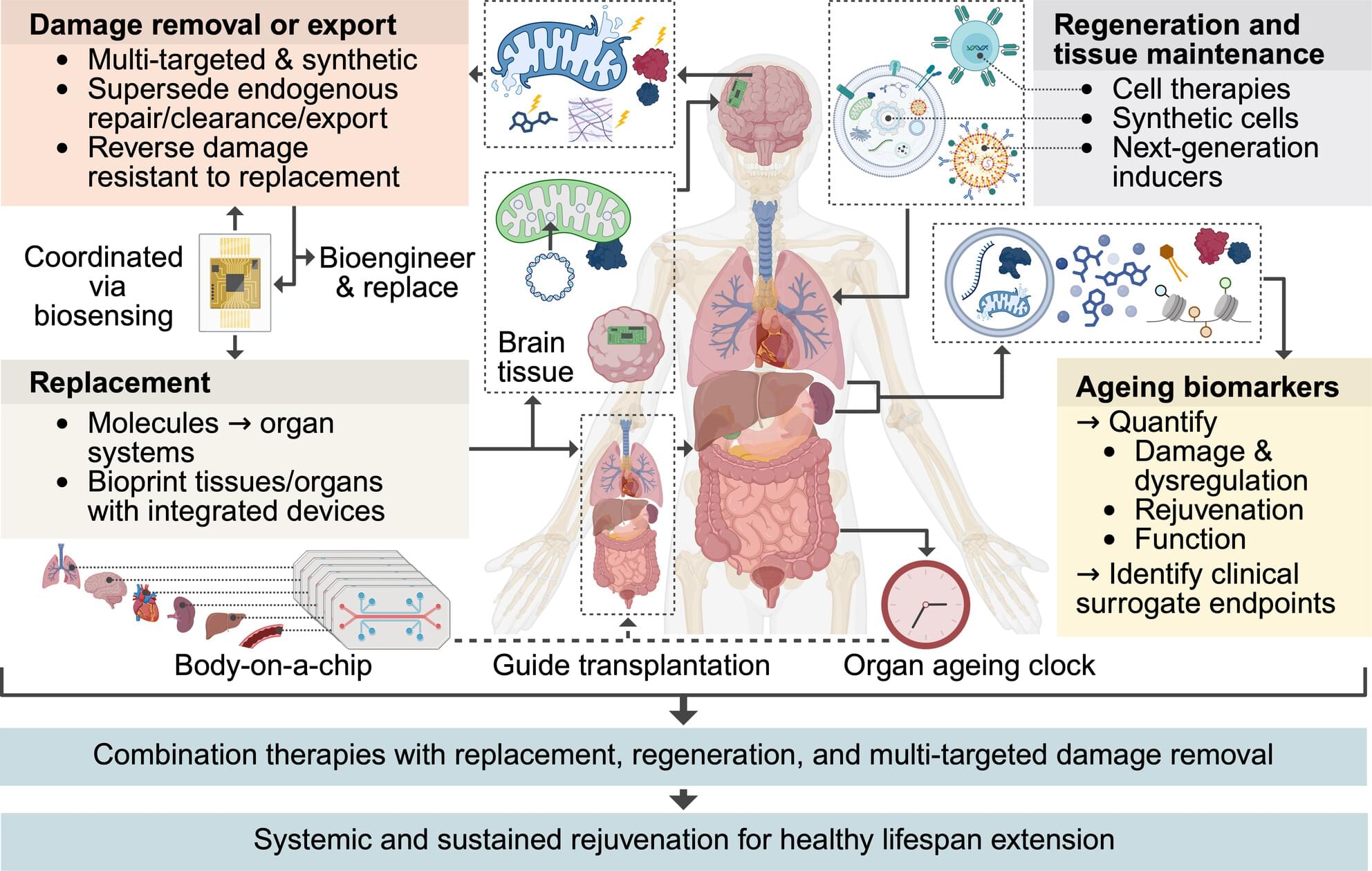
We propose a roadmap to guide research and innovation integrating replacement and next-generation damage-removal therapeutics to modulate the ageing process in the whole body, restore biological function, and extend healthy lifespan.

Are science and religion enemies or allies?
I recorded this debate 14 years ago, and the question has only gotten sharper.
Lincoln Cannon is a software engineer with degrees in philosophy and business. He is also president of the Mormon Transhumanist Association. So when he argues that science and religion are complementary, he is not speaking from ignorance of either side.
I disagree with him. I think they are mutually exclusive. He thinks they complete each other.
So we sat down and argued it out. Friendly, but real.
This was a special edition of Singularity. FM, and it remains one of the more honest conversations I have had about belief, reason, and what transhumanism owes to both. The questions we wrestled with sit right at the heart of #transhumanism and the #futureofreligion in an age of accelerating #technology.
I think this was one of my most enjoyable dialogues in our What’s new series. Maybe Sabine and I are getting more used to each other’s cadence and interests or maybe it was the subject matter. Either way, I think you will find this to be a fascinating and provocative discussion of science at the forefront, and at the not-so-forefront, because that science is interesting too! We began our discussion describing a new finding of a Giant Ring of galaxies billions of light years across in the sky. The key questions are: Is it real? And is it surprising? We both have slightly different takes on this. Next we described a new measurement of the strength of gravity on scales from 80 to 800 million light years in distance. And guess what? Gravity falls off just like Newton predicted! This may seem like a big yawn, but one of the most popular models that claims to do away with dark matter would imply that Gravity would fall off differently on these scales. Does this new result kill that idea? Stay tuned. Microsoft, which has cried wolf a number of times so far when it comes to something called Majorana qubits as the basis of a new viable quantum computer just published a new paper claiming they finally have it. Sabine and I discuss why we are both still skeptical, but why the effort is worth it. Next, CERN, the large European particle physics laboratory, and the world particle physics community seem to have converged on plans for building a huge new accelerator in the current CERN site… this time involving an underground ring 91 km in circumference, in which electrons and positrons would collide to explore the detailed properties of the Higgs particle. Is the effort worth it? Again, Sabine and I have slightly different takes on this. Fusion power, which we have talked about in a number of earlier episodes, continues to tempt humanity with the promise of unlimited energy. Many people, myself included, have tended to argue that fusion seems to be 25 years in the future, and may always be 25 years in the future. But many new efforts are underway, so who knows. Unfortunately, a group of economists has analyzed fusion in the context of other large energy programs and have argued that even if we can achieve it, it may not be as economically viable as many claim. Finally, one day Richard Feynman went to a Thai restaurant with his young companion Ralph Leighton, and wondered what he should order. Should it be the same old dish he loved or something new. An equation filled napkin later, and he had the answer. Fifty years later some cognitive scientists resurrected Feynman’s napkin and explained it, and argued it might have important implications in other social situations. Such is the power of science. Consider supporting the podcast and the Origins Project Foundation at https://www.originsproject.org/ To see commercial-free, full HD video episodes, join us at lawrence krauss.substack.com Thank you for your support! iTunes: https://podcasts.apple.com/us/podcast… https://TheOriginsPodcast.com Twitter: / theoriginspod Instagram:
/ theoriginspod Facebook:
/ theoriginspod The Origins Podcast, a production of The Origins Project Foundation, features in-depth conversations with some of the most interesting people in the world about the issues that impact all of us in the 21st century. Host, theoretical physicist, lecturer, and author, Lawrence M. Krauss, will be joined by guests from a wide range of fields, including science, the arts, and journalism. The topics discussed on The Origins Podcast reflect the full range of the human experience — exploring science and culture in a way that seeks to entertain, educate, and inspire. Full Episodes Playlist:
• Ricky Gervais — The Origins Podcast with L…
Materials list with full instructions: https://www.sciencebuddies.org/science-fair-projects/project…ytid=ZmejS…

Fusion energy is no longer just science fiction — it’s becoming experimental reality. Dr. Mario Manuel, Ph.D. — General Atomics.
What if we could recreate the inside of a star — not in theory, but inside a laboratory on Earth using the world’s most powerful lasers?
Dr. Mario Manuel, Ph.D. is a plasma physicist and laser-science researcher at whose work sits at the frontier of fusion energy, laboratory astrophysics, high-energy-density physics, and advanced laser diagnostics. Trained in applied plasma physics and aerospace engineering, Dr. Manuel has spent his career developing new ways to visualize and understand the extreme electromagnetic environments created when ultra-powerful lasers interact with matter.
Dr. Manuel’s research has spanned some of the most ambitious scientific efforts underway today — from inertial fusion energy and plasma-instability control to recreating supernova-like shock waves in the laboratory and generating ultra-intense gamma-ray and particle beams using petawatt-class lasers.
Early in his career, Dr. Manuel helped pioneer advanced proton-radiography techniques capable of imaging invisible electric and magnetic fields inside laser-produced plasmas, work that opened new windows into the turbulent physics that can either enable or destroy fusion reactions.
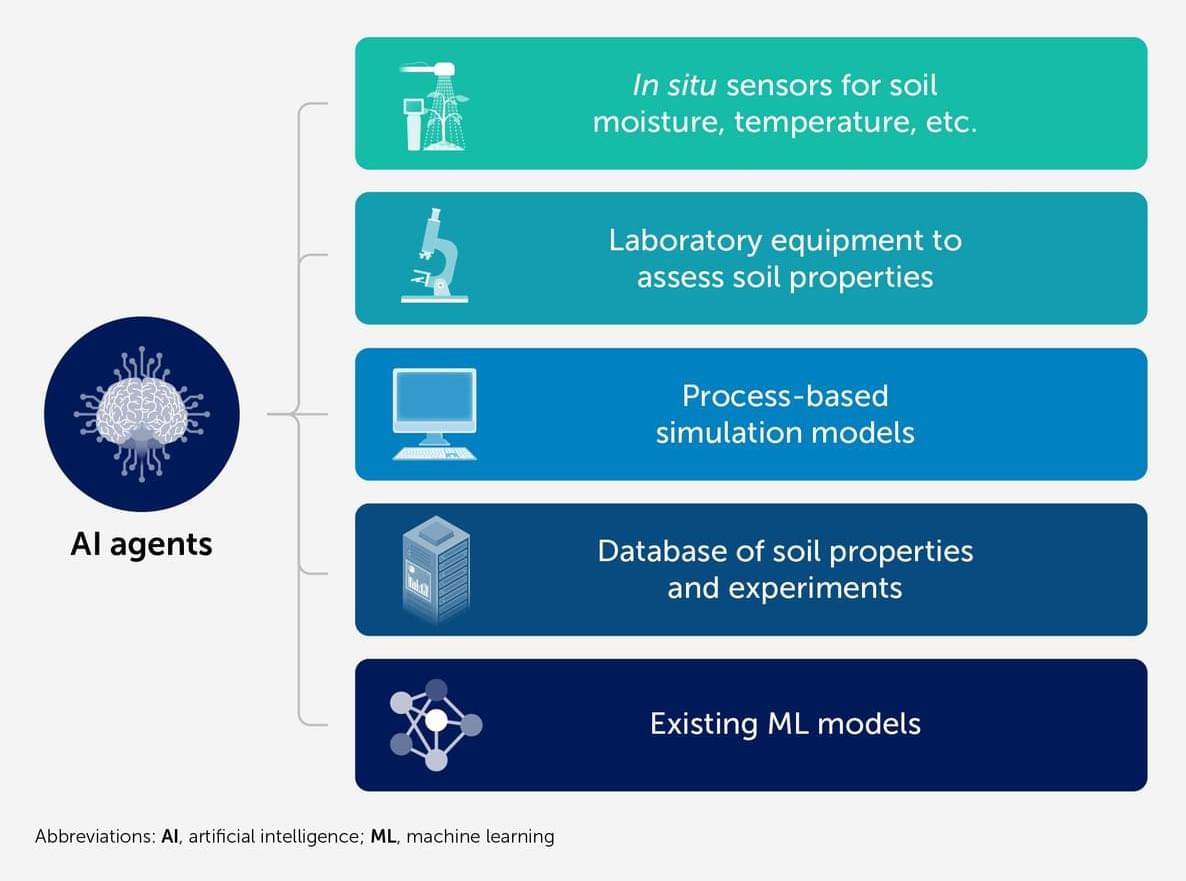
Soil science is entering a new era characterized by the integration of artificial intelligence (AI) multi-agent systems, extending the field beyond traditional machine learning (ML) applications such as digital soil mapping and spectroscopy. While current ML tools are effective for specific tasks, they often lack the reasoning, contextual integration, and adaptability required to address complex, dynamic soil systems. We propose multi-agent AI systems—autonomous, interactive software agents capable of perceptual processing, planning, and scientific reasoning—as a novel framework to support and accelerate soil science research. These agents can fulfill diverse roles, including synthesizing data from field sensors and remote sensing to create dynamic digital soil twins, generating hypotheses, designing experiments, and simulating climate-driven changes in soil function.

What happens when an economist starts designing a future society?
Thirteen years ago, I sat down with Robin Hanson for a second time. It became the most vigorous debate ever recorded.
I rarely disagree with a guest. With Robin, I disagreed more than I ever had.
Here is what unsettled me. His work on the Em Economy reads like social science. It uses the language of markets, incentives, and equilibrium. But underneath the economic reasoning sit choices that are not economic at all. Policies of social discrimination. The full privatization of law and punishment. Minds run a thousand times faster, and handed a thousand times more voting power. Emulations deleted when they cannot pay their storage fees.
These are not technical footnotes. They are ethical and political decisions wearing the costume of impartial analysis.
Adam Smith, the father of economics, was first a moral philosopher. He understood where the tools of his discipline stop being useful and start being dangerous.
For Dijkstra, programming was closer to mathematics than to a craft. The goal wasn’t to “get a feel” for code. The goal was to reason about it rigorously, to understand why it works before discovering whether it works.
The second part of this talk pursues some of the scientific and educational consequences of the assumption that computers represent a radical novelty. In order to give this assumption clear contents, we have to be much more precise as to what we mean in this context by the adjective “radical”. We shall do so in the first part of this talk, in which we shall furthermore supply evidence in support of our assumption.
The usual way in which we plan today for tomorrow is in yesterday’s vocabulary. We do so, because we try to get away with the concepts we are familiar with and that have acquired their meanings in our past experience. Of course, the words and the concepts don’t quite fit because our future differs from our past, but then we stretch them a little bit. Linguists are quite familiar with the phenomenon that the meanings of words evolve over time, but also know that this is a slow and gradual process.
It is the most common way of trying to cope with novelty: by means of metaphors and analogies we try to link the new to the old, the novel to the familiar. Under sufficiently slow and gradual change, it works reasonably well; in the case of a sharp discontinuity, however, the method breaks down: though we may glorify it with the name “common sense”, our past experience is no longer relevant, the analogies become too shallow, and the metaphors become more misleading than illuminating. This is the situation that is characteristic for the “radical” novelty.

I have to confess something about this interview.
I really liked Jacque Fresco. Not as a thinker I was supposed to admire, but as a person: the humor, the humility, the scientific curiosity still burning at 97.
That made the disagreements harder, not easier.
Fresco spent almost a century arguing one idea. We apply the methods of #science to engineering, to medicine, to flight. Then we run our economies and our politics on opinion, tradition, and the preferences of the financial elite.
He thought we had it exactly inverted. Rigor for the machines, guesswork for the humans.
“Technology was never the hard part. The harder question is what kind of society we want it to serve.”