The technology can reconstruct a hidden scene in just minutes using advanced mathematical algorithms.
Potential use case scenarios
Law enforcement agencies could use the technology to gather critical information about a crime scene without disturbing the evidence. This could be especially useful in cases where the scene is dangerous or difficult to access. For example, the technology could be used to reconstruct the scene of a shooting or a hostage situation from a safe distance.
The technology could also have applications in the entertainment industry. For instance, it could create immersive gaming experiences that allow players to explore virtual environments in 3D. It could also be used in the film industry to create more realistic special effects.
The Tokenizer is a necessary and pervasive component of Large Language Models (LLMs), where it translates between strings and tokens (text chunks). Tokenizers are a completely separate stage of the LLM pipeline: they have their own training sets, training algorithms (Byte Pair Encoding), and after training implement two fundamental functions: encode() from strings to tokens, and decode() back from tokens to strings. In this lecture we build from scratch the Tokenizer used in the GPT series from OpenAI. In the process, we will see that a lot of weird behaviors and problems of LLMs actually trace back to tokenization. We’ll go through a number of these issues, discuss why tokenization is at fault, and why someone out there ideally finds a way to delete this stage entirely.
Chapters: 00:00:00 intro: Tokenization, GPT-2 paper, tokenization-related issues. 00:05:50 tokenization by example in a Web UI (tiktokenizer) 00:14:56 strings in Python, Unicode code points. 00:18:15 Unicode byte encodings, ASCII, UTF-8, UTF-16, UTF-32 00:22:47 daydreaming: deleting tokenization. 00:23:50 Byte Pair Encoding (BPE) algorithm walkthrough. 00:27:02 starting the implementation. 00:28:35 counting consecutive pairs, finding most common pair. 00:30:36 merging the most common pair. 00:34:58 training the tokenizer: adding the while loop, compression ratio. 00:39:20 tokenizer/LLM diagram: it is a completely separate stage. 00:42:47 decoding tokens to strings. 00:48:21 encoding strings to tokens. 00:57:36 regex patterns to force splits across categories. 01:11:38 tiktoken library intro, differences between GPT-2/GPT-4 regex. 01:14:59 GPT-2 encoder.py released by OpenAI walkthrough. 01:18:26 special tokens, tiktoken handling of, GPT-2/GPT-4 differences. 01:25:28 minbpe exercise time! write your own GPT-4 tokenizer. 01:28:42 sentencepiece library intro, used to train Llama 2 vocabulary. 01:43:27 how to set vocabulary set? revisiting gpt.py transformer. 01:48:11 training new tokens, example of prompt compression. 01:49:58 multimodal [image, video, audio] tokenization with vector quantization. 01:51:41 revisiting and explaining the quirks of LLM tokenization. 02:10:20 final recommendations. 02:12:50??? smile
Exercises: - Advised flow: reference this document and try to implement the steps before I give away the partial solutions in the video. The full solutions if you’re getting stuck are in the minbpe code https://github.com/karpathy/minbpe/bl…
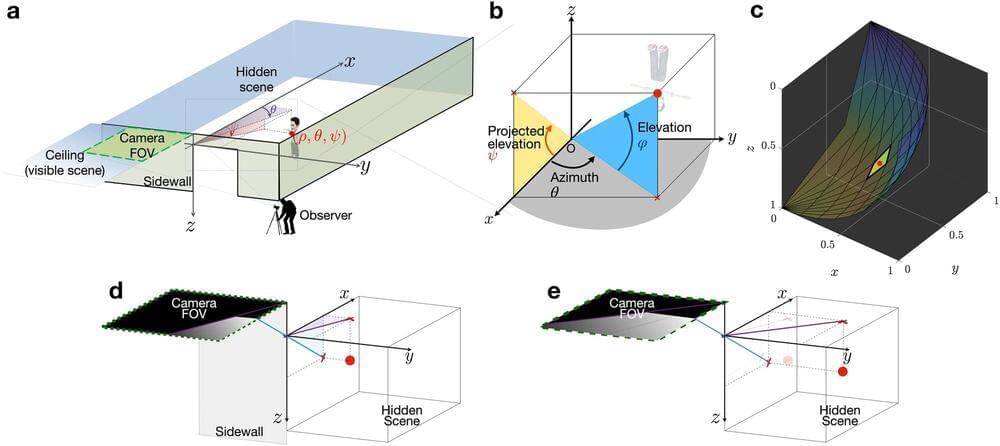
After a recent car crash, John Murray-Bruce wished he could have seen the other car coming. The crash reaffirmed the USF assistant professor of computer science and engineering’s mission to create a technology that could do just that: See around obstacles and ultimately expand one’s line of vision.
Using a single photograph, Murray-Bruce and his doctoral student, Robinson Czajkowski, created an algorithm that computes highly accurate, full-color three-dimensional reconstructions of areas behind obstacles—a concept that can not only help prevent car crashes but help law enforcement experts in hostage situations search-and-rescue and strategic military efforts.
“We’re turning ordinary surfaces into mirrors to reveal regions, objects, and rooms that are outside our line of vision,” Murray-Bruce said. “We live in a 3D world, so obtaining a more complete 3D picture of a scenario can be critical in a number of situations and applications.”
Speaker’s Bio: Catherine (Katie) Schuman is a research scientist at Oak Ridge National Laboratory (ORNL). She received her Ph.D. in Computer Science from the University of Tennessee (UT) in 2015, where she completed her dissertation on the use of evolutionary algorithms to train spiking neural networks for neuromorphic systems. She is continuing her study of algorithms for neuromorphic computing at ORNL. Katie has an adjunct faculty appointment with the Department of Electrical Engineering and Computer Science at UT, where she co-leads the TENNLab neuromorphic computing research group. Katie received the U.S. Department of Energy Early Career Award in 2019.
Talk Abstract: Neuromorphic computing is a popular technology for the future of computing. Much of the focus in neuromorphic computing research and development has focused on new architectures, devices, and materials, rather than in the software, algorithms, and applications of these systems. In this talk, I will overview the field of neuromorphic from the computer science perspective. I will give an introduction to spiking neural networks, as well as some of the most common algorithms used in the field. Finally, I will discuss the potential for using neuromorphic systems in real-world applications from scientific data analysis to autonomous vehicles.
But make no mistake. Their engines are still as mysterious as they were when the German theoretical physicist Karl Schwarzschild first played with Einstein’s field equations and came to the conclusion that space and time could pucker up into pits of no return.
Goethe University Frankfurt physicists Daniel Jampolski and Luciano Rezzolla have gone back to step one in an attempt to make better sense of the equations that describe black holes and have come away with a solution that’s easier to picture, if no less bizarre.
The human brain is probably the most complex thing in the universe. Apart from the human brain, no other system can automatically acquire new information and learn new skills, perform multimodal collaborative perception and information memory processing, make effective decisions in complex environments, and work stably with low power consumption. In this way, brain-inspired research can greatly advance the development of a new generation of artificial intelligence (AI) technologies.
Powered by new machine learning algorithms, effective large-scale labeled datasets, and superior computing power, AI programs have surpassed humans in speed and accuracy on certain tasks. However, most of the existing AI systems solve practical tasks from a computational perspective, eschewing most neuroscientific details, and tending to brute force optimization and large amounts of input data, making the implemented intelligent systems only suitable for solving specific types of problems. The long-term goal of brain-inspired intelligence research is to realize a general intelligent system. The main task is to integrate the understanding of multi-scale structure of the human brain and its information processing mechanisms, and build a cognitive brain computing model that simulates the cognitive function of the brain.
The Schwartz Reisman Institute for Technology and Society and the Department of Computer Science at the University of Toronto, in collaboration with the Vector Institute for Artificial Intelligence and the Cosmic Future Initiative at the Faculty of Arts & Science, present Geoffrey Hinton on October 27, 2023, at the University of Toronto.
0:00:00 — 0:07:20 Opening remarks and introduction. 0:07:21 — 0:08:43 Overview. 0:08:44 — 0:20:08 Two different ways to do computation. 0:20:09 — 0:30:11 Do large language models really understand what they are saying? 0:30:12 — 0:49:50 The first neural net language model and how it works. 0:49:51 — 0:57:24 Will we be able to control super-intelligence once it surpasses our intelligence? 0:57:25 — 1:03:18 Does digital intelligence have subjective experience? 1:03:19 — 1:55:36 Q&A 1:55:37 — 1:58:37 Closing remarks.
Talk title: “Will digital intelligence replace biological intelligence?”
Abstract: Digital computers were designed to allow a person to tell them exactly what to do. They require high energy and precise fabrication, but in return they allow exactly the same model to be run on physically different pieces of hardware, which makes the model immortal. For computers that learn what to do, we could abandon the fundamental principle that the software should be separable from the hardware and mimic biology by using very low power analog computation that makes use of the idiosynchratic properties of a particular piece of hardware. This requires a learning algorithm that can make use of the analog properties without having a good model of those properties. Using the idiosynchratic analog properties of the hardware makes the computation mortal. When the hardware dies, so does the learned knowledge. The knowledge can be transferred to a younger analog computer by getting the younger computer to mimic the outputs of the older one but education is a slow and painful process. By contrast, digital computation makes it possible to run many copies of exactly the same model on different pieces of hardware. Thousands of identical digital agents can look at thousands of different datasets and share what they have learned very efficiently by averaging their weight changes. That is why chatbots like GPT-4 and Gemini can learn thousands of times more than any one person. Also, digital computation can use the backpropagation learning procedure which scales much better than any procedure yet found for analog hardware. This leads me to believe that large-scale digital computation is probably far better at acquiring knowledge than biological computation and may soon be much more intelligent than us. The fact that digital intelligences are immortal and did not evolve should make them less susceptible to religion and wars, but if a digital super-intelligence ever wanted to take control it is unlikely that we could stop it, so the most urgent research question in AI is how to ensure that they never want to take control.
About Geoffrey Hinton.
Geoffrey Hinton received his PhD in artificial intelligence from Edinburgh in 1978. After five years as a faculty member at Carnegie Mellon he became a fellow of the Canadian Institute for Advanced Research and moved to the Department of Computer Science at the University of Toronto, where he is now an emeritus professor. In 2013, Google acquired Hinton’s neural networks startup, DNN research, which developed out of his research at U of T. Subsequently, Hinton was a Vice President and Engineering Fellow at Google until 2023. He is a founder of the Vector Institute for Artificial Intelligence where he continues to serve as Chief Scientific Adviser.
Sarcasm, a complex linguistic phenomenon often found in online communication, often serves as a means to express deep-seated opinions or emotions in a particular manner that can be in some sense witty, passive-aggressive, or more often than not demeaning or ridiculing to the person being addressed. Recognizing sarcasm in the written word is crucial for understanding the true intent behind a given statement, particularly when we are considering social media or online customer reviews.
While spotting that someone is being sarcastic in the offline world is usually fairly easy given facial expression, body language and other indicators, it is harder to decipher sarcasm in online text. New work published in the International Journal of Wireless and Mobile Computing hopes to meet this challenge. Geeta Abakash Sahu and Manoj Hudnurkar of the Symbiosis International University in Pune, India, have developed an advanced sarcasm detection model aimed at accurately identifying sarcastic remarks in digital conversations, a task crucial for understanding the true intent behind online statements.
The team’s model comprises four main phases. It begins with text pre-processing, which involves filtering out common, or “noise,” words such as “the,” “it,” and “and.” It then breaks down the text into smaller units. To address the challenge of dealing with a large number of features, the team used optimal feature selection techniques to ensure the model’s efficiency by prioritizing only the most relevant features. Features indicative of sarcasm, such as information gain, chi-square, mutual information, and symmetrical uncertainty, are then extracted from this pre-processed data by the algorithm.
It’s electric! A startup emerged from stealth this week with grand plans to pioneer a new form of neurotech dubbed “electric medicine.”
Elemind’s approach centers on artificial intelligence-powered algorithms that are trained to continuously analyze neurological activity collected by a noninvasive wearable device, then to deliver through the wearable bursts of neurostimulation that are uniquely tailored to those real-time brain wave readings.