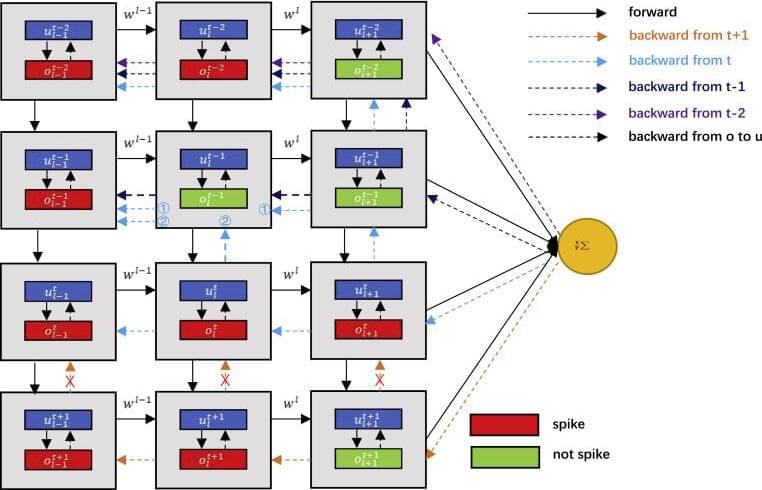
Spiking neural networks (SNNs) capture the most important aspects of brain information processing. They are considered a promising approach for next-generation artificial intelligence. However, the biggest problem restricting the development of SNNs is the training algorithm.
To solve this problem, a research team led by Prof. Zeng Yi from the Institute of Automation of the Chinese Academy of Sciences has proposed backpropagation (BP) with biologically plausible spatiotemporal adjustment for training deep spiking neural networks.
The associated study was published in Patterns on June 2.