Superconductors (materials that conduct electricity without resistance) have fascinated physicists for more than a century. While conventional superconductors are well understood, a new class of materials known as topological superconductors has attracted intense interest in recent years.
These superconductors have been reported to be capable of hosting Majorana quasiparticles, exotic states that could change the field of fault-tolerant quantum computing. Yet many of the fundamental properties of these novel bulk topological superconductors remain relatively unknown, leaving open questions about how their unusual electronic states interact with the underlying crystal lattice.
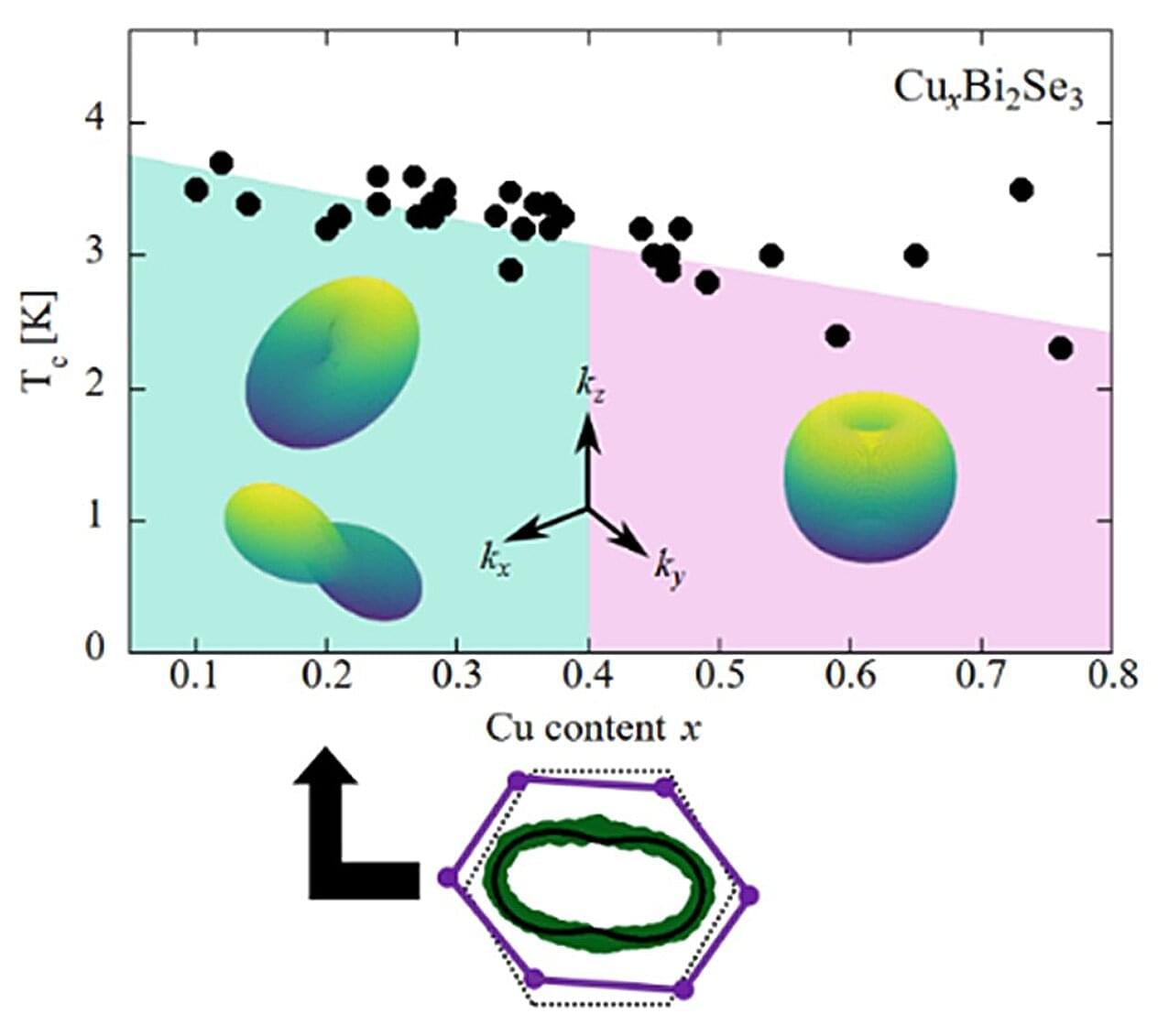
In a new study conducted by Professor Guo-qing Zheng, along with Kazuaki Matano, S. Takayanagi, K. Ito of Okayama University and Professor H. Nakao of High Energy Accelerator Research Organization (KEK), published in Physical Review Letters on August 22, 2025, the researchers report that the doped topological insulator CuxBi2Se3 undergoes tiny but spontaneous distortions in its crystal lattice as it enters the superconducting state.