Scientists want to simulate various climate conditions to help prevent real life risks to our planet.


# spacebear.
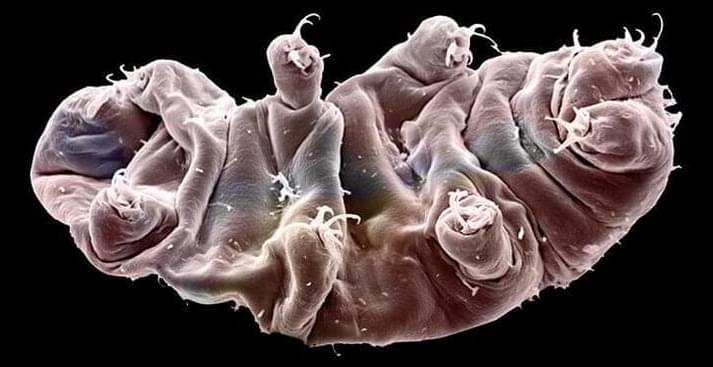
Just over five years ago, on 22 February 2019, an unmanned space probe was placed in orbit around the Moon.
Named Beresheet and built by SpaceIL and Israel Aerospace Industries, it was intended to be the first private spacecraft to perform a soft landing. Among the probe’s payload were tardigrades, renowed for their ability to survive in even the harshest climates.
The mission ran into trouble from the start, with the failure of “star tracker” cameras intended to determine the spacecraft’s orientation and thus properly control its motors. Budgetary limitations had imposed a pared-down design, and while the command center was able to work around some problems, things got even trickier on 11 April, the day of the landing.


A chemical etching method for widening the pores of metal-organic frameworks (MOFs) could improve various applications of MOFs, including in fuel cells and as catalysts. Researchers at Nagoya University in Japan and East China Normal University in China developed the new method with collaborators elsewhere in Japan, Australia, and China, and their work was published in the Journal of the American Chemical Society.
MOFs are porous materials composed of metal clusters or ions interconnected by carbon-based (organic) linker groups. Varying the metallic and organic components generates a variety of MOFs suitable for a wide range of applications, including catalysis, chemical separation, and gas storage.
Some MOFs have clear potential for catalyzing the chemical reactions inside fuel cells, which are being explored as the basis of renewable energy systems. Because they don’t use fossil fuels, fuel cells could play a key role in the transition to a low-or zero-emissions economy to combat climate change.

An interesting exploration of the importance of oceanic microorganisms to biogeochemical processes, how existing computational climate models do not adequately capture the complexity introduced by these microbes, and suggestions for future directions in climate modeling that better incorporate the…
Microorganisms are the engines that drive most marine processes. Ocean modelling must evolve to take their biological complexity into account.

Everybody knows that the public fast-charging life is just easier when you’re a Tesla owner. But starting today, Ford F-150 Lightning and Mustang Mach-E owners will begin to play on their level too as the Tesla Supercharger network opens up to them.
Ford today announced two major developments on the electric front. First, Ford customers can now order the Fast Charging Adapter—the first from a major automaker—that allows Tesla North American Charging Standard (NACS) plugs to link up to the Combined Charging System (CCS) fast-charging port standard on basically all non-Tesla EVs.
The Voyager 1 was launched in 1977. Almost 50 years later, it’s still going and sending back information, penetrating ever deeper into space. It can do that because it’s powered by nuclear energy.
Long a controversial energy source, nuclear has been experiencing renewed interest on Earth to power our fight against climate change. But behind the scenes, nuclear has also been facing a renaissance in space.
In July, the US National Aeronautics and Space Administration (NASA) and Defense Advanced Research Projects Agency (DARPA) jointly announced that they plan to launch a nuclear-propelled spacecraft by 2025 or 2026. The European Space Agency (ESA) in turn is funding a range of studies on the use of nuclear engines for space exploration. And last year, NASA awarded a contract to Westinghouse to develop a concept for a nuclear reactor to power a future moon base.
Azeem speaks with Professor Yoshua Bengio. In 2018, Yoshua, Geoff Hinton and Yann LeCun were awarded the Turing Award for advancing the field of AI, in particular for their groundbreaking conceptual and engineering research in deep learning. This earnt them the moniker the Three Musketeers of Deep Learning. I think Bengio might be Aramis: intellectual, somewhat pensive, with aspirations beyond combat, and yet skilled with the blade.
With 750,000 citations to his scientific research, Yoshua has turned to the humanistic dimension of AI, in particular, the questions of safety, democracy, and climate change. Yoshua and I sit on the OECD’s Expert Group on AI Futures.

A recent study from UNSW Sydney demonstrates that significant reductions in the temperatures of major cities located in hot desert climates can be achieved alongside decreases in energy expenses.
The findings, recently published in Nature Cities, detail a multi-faceted strategy to cool Saudi Arabia’s capital city by up to 4.5°C, combining highly reflective ‘super cool’ building materials developed by the High-Performance Architecture Lab with irrigated greenery and energy retrofitting measures. The study, which was conducted in collaboration with the Royal Commission of Riyadh, is the first to investigate the large-scale energy benefits of modern heat mitigation technologies when implemented in a city.
“The project demonstrates the tremendous impact advanced heat mitigation technologies and techniques can have to reduce urban overheating, decrease cooling needs, and improve lives,” says UNSW Scientia Professor Mattheos (Mat) Santamouris, Anita Lawrence Chair in High-Performance Architecture and senior author of the study.
{kind=link}