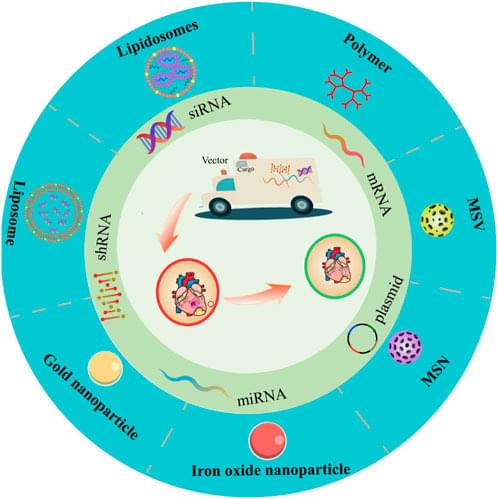
Gene therapy is a technique that rectifies defective or abnormal genes by introducing exogenous genes into target cells to cure the disease. Although gene therapy has gained some accomplishment for the diagnosis and therapy of inherited or acquired cardiovascular diseases, how to efficiently and specifically deliver targeted genes to the lesion sites without being cleared by the blood system remains challenging. Based on nanotechnology development, the non-viral vectors provide a promising strategy for overcoming the difficulties in gene therapy. At present, according to the physicochemical properties, nanotechnology-based non-viral vectors include polymers, liposomes, lipid nanoparticles, and inorganic nanoparticles. Non-viral vectors have an advantage in safety, efficiency, and easy production, possessing potential clinical application value when compared with viral vectors. Therefore, we summarized recent research progress of gene therapy for cardiovascular diseases based on commonly used non-viral vectors, hopefully providing guidance and orientation for future relevant research.
Cardiovascular disease (CVD) leads to almost a third of all deaths worldwide, resulting from atherosclerotic plaque leading to hemadostenosis and blood flow restriction (Park et al., 2020; Tsao et al., 2022). Despite progress in medical technology, CVD is still a major cause of death (Yang et al., 2023). Conventional treatment strategies for CVD include anticoagulation, antiplatelet, thrombolytics, hypolipidemic drugs, and invasive therapies like vascular bypass grafting and stent transplantation (Zhu et al., 2021). However, small molecule drug therapy in conventional treatment strategies is characterized by short half-life and low bioavailability, and long-term use of certain drugs may also lead to side effects such as drug resistance and potential hematological toxicity (Missri, 1979; Fu et al., 2014). Surgical treatment, on the other hand, is more pro-traumatic, requires a longer recovery time, and has a high risk of postoperative complications.




{kind=link}